Introduction
On July 14th, 2025, StarkWare engaged zkSecurity to perform a three-week audit on the Stwo-Cairo verifier, which is a Cairo implementation of a verifier for the Stwo protocol.
Scope
The audit focused on the stwo_cairo_verifier component in the Stwo-Cairo repository, at commit aef7d09.
The StarkWare team also provided us with a draft of the Stwo whitepaper, which we used as a reference for the theoretical background of the protocol.
Summary and recommendations
Overall, we found the verifier code to be well written and organized. A caveat is that the Cairo verifier did not successfully compile at the time of audit. As a fallback, we could use a Rust implementation of the same verifier in stwo_cairo_prover to run end-to-end tests and proof-of-concepts.
Apart from the concrete findings listed at the end of this report, we have some strategic recommendations for keeping the code base secure in the longer term:
-
Validate prover-supplied data structures. We found that the verifier accepts several data structures from the prover without proper validation, as documented in two findings (1, 2). For example, zipping a verifier-validated array with a prover-provided one without validating lengths, or not checking that two different, related Option values provided by the prover are consistent. In general, the rule of thumb should be that whenever data from the proof is allowed to shape the verifier algorithm, it should be subject to some form of validation.
-
Be careful about hash collisions. We identified multiple sources of hash collisions throughout the codebase, see 1, 2. While we found no direct exploits, these collisions complicate security analysis and could become exploitable in unexpected ways. We recommend to avoid hash collisions more consistently.
-
Keep consistency between the code and whitepaper. During our audit, we discovered a few divergences between the core verifier implementation and the Stwo whitepaper. Divergences that are not directly exploitable were nonetheless recorded and reported as informational findings. Indeed, they are an indication that the deployed proof system may not fall directly under the security proof in the whitepaper. We recommend (re-)establishing consistency between the two.
-
Document overall Cairo AIR structure. The Cairo AIR implements a sophisticated flat AIR architecture with multiple tables connected through LogUp arguments, with many interesting variations like opcodes tables, memory, builtins, chained rounds, etc. However, the overall structure, table variations and table relationships are not comprehensively documented, creating a barrier for newcomers to understand and review the code. We recommend creating high-level documentation of the complete AIR structure, including how the lookup relations ensure Cairo program execution correctness.
Overview of Key Concepts
Stwo, Cairo and stwo-cairo
Before diving into the report, it may be helpful for readers that we define and differentiate between “Stwo”, “Cairo” and the repository being reviewed, stwo-cairo.
Stwo. “Stwo” refers to two things: a non-interactive STARK (alt. transparent SNARK) protocol and a Rust-based implementation of the protocol. The STARK is based on Circle STARK [HLP24] and allows to prove the satisfaction of an AIR with additional features such as preprocessed and randomized columns. The protocol is described in an upcoming whitepaper which the Client has provided us with a draft version of. To avoid ambiguity throughout the report:
- we refer to Stwo, the non-interactive STARK protocol, as the Stwo whitepaper or the Stwo protocol.
- we refer to Stwo, the Rust implementation of the Stwo protocol, as
stwo-rs.
Cairo. As explained in the Cairo documentation, “Cairo” is a tech stack that comprises multiple elements. Among them, we highlight:
- CairoVM, a virtual machine (VM) that is designed in such a way that its valid execution can be efficiently expressed as an AIR. This property is sometimes abbreviated as “SNARK-friendly” or “STARK-friendly”.
- Cairo, a Rust-based high-level language that can be compiled to assembly code for the CairoVM.
We stay consistent with the terms defined in the Cairo documentation and will now use Cairo and CairoVM unambiguously and as above. We also define the CairoAIR to be any (preprocessed and randomized) AIR that enforces the valid execution of the CairoVM.
stwo-cairo. As its name indicates, stwo-cairo is a combination of many of the above elements. The repository contains:
- the definition of a CairoAIR. This is in fact a particular type of AIR with preprocessed and randomized columns defined in the Stwo whitepaper as a flat AIR.
- a Rust-based prover that implements the Stwo protocol prover for the CairoAIR.
- a Cairo-based verifier,
stwo_cairo_verifier, which implements the Stwo protocol verifier for the CairoAIR. This can be understood as the Cairo counterpart to the verifier in stwo-rs, specialized for the CairoAIR.
The latter component is the object of this audit. Writing a Cairo-based verifier for validity proofs of the CairoVM is of particular interest as it enables recursive proof composition. This technique is highly prevalent in high-performance SNARK/STARK stacks as it allows for proof aggregation (combining many proofs into one) and continuations (breaking up a large program’s execution into multiple sub-proofs).
The M31 Field and Extensions
Following the Stwo whitepaper, we write to denote the finite field of order
We assume that readers are familiar with the field, the circle curve and circle polynomials over a prime or extension field . We direct the interested reader to our introductory material on these topics (Part 1, Mersenne, Part 2, Circles and Part 3, FFT).
Secure extensions. The field is too small to yield the desired security level for the Stwo protocol. To remediate this, the protocol samples challenges from a degree- extension of . Once again following the Stwo whitepaper, we define the following extensions fields:
- the complex extension is constructed as We write and express elements of as
- the quartic extension is constructed as We write and express elements of as
The flat AIR
A flat AIR is a collection of AIR tables, each with their own dimensions and constraints.
The tables are “connected” by enforcing the equality of partial rows across tables via a lookup argument.
This setup provides a more flexible arithmetization than a classic monolithic AIR. Flat AIRs allow a ZKVM design to dedicate one table per gate, opcode or even full operations such as a hash function. By constraining operations in separate tables, flat AIRs ensure that each table is kept to the minimum number of columns required for its own set of constraints.
This approach is also referred to as a “multi-table STARK” or a “precompile-centric design”, since the notion of dedicating a table to an operation first emerged with the idea of precompiles.
Lookups between the tables
Stwo uses the LogUp lookup argument to verify that every element in one sequence appears in another. Given two sequences and , and letting denote the multiplicity of in , the argument relies on the identity:
When and reside in different tables, the prover first commits to the vector of multiplicities (or, in some cases, they are hard-coded to particular constant values).
The verifier then samples a random point , and the prover provides commitments to the interaction columns along with the claimed sums:
The verifier enforces AIR constraints on the original tables to confirm these sums and finally checks that .
To support lookups across multiple columns simultaneously, Stwo replaces each element by a random linear combination of the original columns.
For example, for column pairs and , it tests:
at a random point and a random folding factor .
When handling several lookup relations, the verifier chooses independent challenges for each pair, aggregates all resulting sums, and checks that their total equals zero. For instance, with lookups and , it verifies:
We note that soundness follows from applying the Schwartz–Zippel lemma in the multivariate setting, and is only guaranteed if challenges for each lookup pair are distinct.
Circle Polynomials over QM31
Throughout the execution of the protocol, the verifier will be required to evaluate and apply constraints to circle polynomials over . These polynomials appear in the LogUp rounds, during the construction of the randomized columns of the components AIRs, and when running the univariate zero test on the composition polynomial.
In order to apply constraints to the LogUp polynomials, these must be added as columns to the component AIRs. However, all AIRs are defined over and columns cannot contain elements of .
This tension is resolved by representing a single circle polynomial over as four circle polynomials over with the following joining rule
In addition to solving the tension mentioned above, this method of polynomial representation greatly simplifies the verifier’s logic. Every polynomial received by the verifier is now a circle polynomial over , avoiding the need for (and pitfalls of) managing oracles over different alphabets.
Multi-vector Commitment Scheme from Merkle Trees
Protocols for AIR satisfiability usually require to commit to each of the columns in the AIR table. A common optimization, as detailed here, consists in committing the whole table in a single Merkle tree, where the -th leaf node contains the values of all the columns at row .
Stwo applies a similar optimization to its flat AIR arithmetization. However, a flat AIR is composed of multiple tables with different column lengths. Naively committing to a flat AIR would result in producing one Merkle root per table.
To avoid this, Stwo uses modified Merkle trees that allow internal tree nodes to also carry data. We give an illustrated example below constructing a tree of depth that commits to three vectors, two of length and one of length .
Circle FRI
Like univariate FRI, the Circle FRI protocol tests whether a committed function is close to a Reed–Solomon codeword.
However, instead of operating on a univariate polynomial, the committed function is defined over a circle domain in .
The protocol iteratively reduces the domain size by folding the function into its even and odd parts until the domain is small enough for direct testing. In Circle FRI, this folding is achieved using two 2-to-1 maps:
- point doubling, which sends a circle group element to its double (denoted ), and
- x-axis projection, which maps a circle group element to its x-coordinate (denoted ).
Crucially, the x-coordinate of the doubled point can be computed without the y-coordinate.
Therefore, we first apply the x-axis projection and then iteratively apply point doubling.
This process is illustrated in the following diagram.
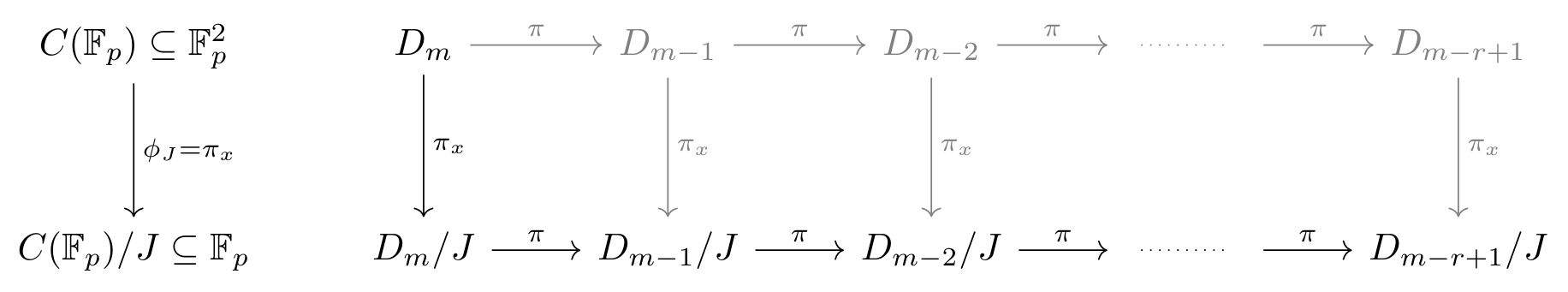
We also note that the x-axis projection maps each point to its x-coordinate, flattening the domain for folding to a line.
Pipelining Circle FRI
Another consequence of the flat AIR arithmetization is that the proof system now requires to run a batched proximity test for many vectors of different sizes. Padding all vectors to the size of the largest vector would undermine some of the savings provided by the flat AIR. Instead, Stwo implements an optimization that is also present in plonky2/3 and is referred to as pipelining.
The idea stems from the observation that FRI naturally produces domains and vectors of decreasing sizes during the commit phase. Rather than padding all vectors to the size of the largest domain, a pipelined implementation of FRI batches vectors at their corresponding step of the FRI commit phase.
Consider the following example: testing proximity of vectors and to a Reed-Solomon code, where . Following the folding procedure, the prover computes the even and odd components of which we will denote and respectively. In the classic FRI protocol, the prover is given a verifier challenge and would send the oracle . However, in a pipelined implementation, we take advantage of the fact that and instead compute:
The rest of the protocol proceeds as normal, unless there are smaller vectors that need to be inserted.
The above example is shown with regular polynomials. Working with circle polynomials introduces small complications which are explained and dealt with in the Stwo whitepaper. We also note that, to the best of our knowledge, the Stwo whitepaper is the first resource that proves the soundness of this batching method.
Proving polynomial evaluations using FRI
In STARKs, the FRI protocol can be turned into an evaluation proof via a standard quotienting technique.
The verifier first receives an oracle for the original polynomial as a vector of evaluations in .
Next, they sample a random out-of-domain circle point and request the evaluation .
The prover sends the purported value , and then both prover and verifier engage in a low-degree test using FRI on the quotient:
Here, is the unique linear polynomial interpolating and , while vanishes at and .
The notation denotes the complex conjugate of in in the second extension.
We note that this works because for any polynomial over the base field , we have .
As in the univariate case, if is a low-degree polynomial rather than a rational function, the verifier is convinced that the evaluation claim is correct, i.e., that .
FRI and Pipelining in Stwo-Cairo
In Stwo-Cairo, folding is handled by the fri component.
During the commit phase, the prover repeatedly commits to oracle polynomials while the verifier issues a folding challenge at each step.
After the final round, the prover reveals the last polynomial in the clear.
In the decommitment phase, the verifier selects query positions in the initial layer and requests the corresponding evaluations from the prover.
For each step, the verifier also checks the Merkle authentication paths for the queried evaluations.
It then uses these values to iteratively fold and compute the expected evaluations at each successive layer.
At the end, the verifier obtains queries and expected evaluations for the final polynomial, which it verifies by direct evaluation at those points.
To support pipelining, the verifier applies an x-axis projection to all committed columns before performing a pipelined folding of those columns using the point-doubling map.
CairoAIR
CairoAIR is an AIR that proves that a Cairo program was executed correctly (i.e. according to the semantics of the CairoVM).
CairoVM
To give a brief introduction to CairoVM, the CairoVM contains a read-only memory and a CPU with 3 registers (pc, ap, fp) that executes a single Cairo instruction every step. As can be seen in the figure below, a Cairo instruction is composed of 64 bits, where the first 3 16-bits represent the offsets to the 3 operands (dst, op0, op1) that the instruction uses.

The next 15 bits are flags which determine which of the registers to use for the operands and how the 3 registers should be updated after execution. It also determines which opcode to use for the instruction, where each unique opcode defines a custom logic for the instruction. Every Cairo instruction is mapped to a specific opcode, which can range from basic computation (e.g. ADD or MUL opcodes) to programming language specific ones (e.g. CALL, RET). CairoAIR extends the functionality of a Cairo instruction defined in the Cairo paper to define custom opcodes using an opcode_extension field. Essentially, a Cairo instruction is expanded to 72 bits and the last 9 bits (64 to 72) are allocated for the opcode_extension field. Currently, the following opcode extension values are supported:
0: Stone, which are the original opcodes defined in the Cairo paper1: Blake2: BlakeFinalize3: QM31Operation
The AIR
We now give a simplified version of how the CairoAIR proves that the correct execution of a Cairo program.
The verifier is given only the following values:
- The initial and final values of the 3 registers (
pc, ap, fp)
- The Cairo program, which is a set of Cairo instructions
and the prover needs to prove the following:
- Each Cairo instruction was executed correctly according to the CairoVM semantics
- The Cairo program was executed on the initial register values and resulted in the final register values
- The memory values accessed during the execution of the Cairo program do not violate the read-only memory model
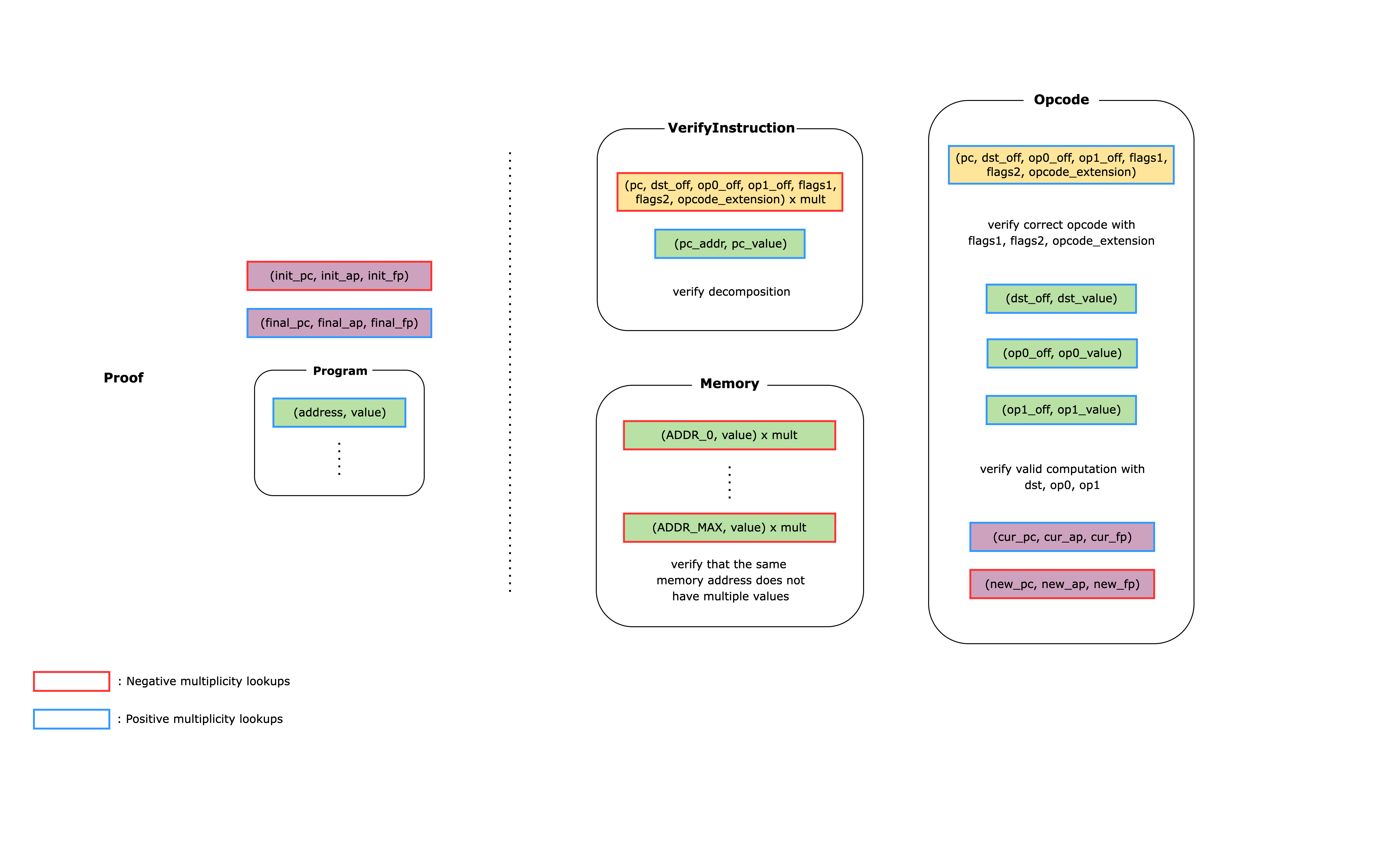
The CairoAIR implements these checks using a flat AIR (i.e. multiple tables that are connected to each other using lookups). Below is a simplified diagram of what the CairoAIR looks like.
The rounded rectangles on the right-hand side of the diagram each represent a unique table that the prover constructs as part of the witness. The left-hand side shows the public values that are given to the verifier: the initial and final values of the 3 registers and the Cairo program. Each non-rounded rectangle represents a lookup relation where red edges means a lookup relation with a negative multiplicity and blue edges mean a lookup relation with a positive multiplicity. Each non-rounded rectangle with the same fill colors represent lookup relations that are connected to each other. When verifying the proof, the verifier can simply check that the total sum of the values in all the non-rounded rectangles is equal to zero.
We now show how this AIR can prove what the bullet points mentioned above:
- To determine which opcode to use for the instruction, we need to first read the instruction from memory using the
pc register value and decompose it into offsets and flags. Reading the instruction and decomposing it is done inside the VerifyInstruction table and the result is looked up by the Opcode table using the (pc, dst_off, op0_off, op1_off, flags1, flags2, opcode_extension) relation. Then, using the offsets and the flags, we read the values of the operands from the Memory table using the (dst_off, dst_value), (op0_off, op0_value), and (op1_off, op1_value) relations. Finally, we check that the computation for the corresponding opcode is done correctly using the constraints in the Opcode table.
- The
Opcode table also updates the register values according to the flags in the instruction. This means that if we lookup the input register values for an instruction as positive and the output register values for the same instruction as negative, when adding all the lookup relations together, everything will cancel out except for the input to the first instruction and the output of the last instruction. Since these register values are public to the verifier, the verifier can simply subtract (init_pc, init_ap, init_fp) and add (final_pc, final_ap, final_fp) to the total claimed sum and check that it equals zero.
- To check the validity of the read-only memory, we need to check that each memory address does not map to multiple values. To do this, the
Memory table makes sure that only one row can be defined per address. Whenever we need to access a value in memory, we add a (addr, value) relation, while the Memory table subtracts the same relation. Since there can be multiple accesses to the same memory address, the Memory table also has a multiplicity column that is used to multiply the (addr, value) relation. Note that in the actual stwo-cairo code, the memory address is first mapped to an id and then the id is mapped to the value, but we omit this for brevity.
The AddOpcode table
To give an example of how an Opcode table is implemented, we give an overview of the AddOpcode table.
As we saw in the previous section, an Opcode table does the following:
- uses the
VerifyInstruction table to decompose the instruction into offsets and flags.
- verifies that the instruction corresponds to the current opcode using the flags.
- uses the
Memory table to get the values of the operands op0, op1, and dst.
- verifies that the opcode operation is done correctly.
- updates the 3 register values (
pc, ap, fp) using the flags.
In this section, we go over how the AddOpcode table implements step 4 since the other steps are general for all Opcode tables and were already covered.
Assuming that the operands op0, op1, and dst are correctly accessed from the Memory table, the main constraint of the AddOpcode table is to check that op0 + op1 = dst. But before diving deeper into the constraints, we need to understand that Cairo and Stwo use different fields and thus we need to convert between them. Cairo works over the 252-bit prime field , while Stwo works over the 31-bit prime field . CairoAIR decomposes the 252-bit integers into 28 9-bit limbs and range checks that each limb is in the range .
To check that the two sets of limbs are correctly added, we iterate from the least significant limb to the most significant limb. For each limb except for the first, we also need to take into account the carry from the previous limb. This check of additions over multiple limbs is done over a single constraint as there is no multiplication involved and we don’t need to worry about the degree of the constraint. For example, the first limb computes carry_limb_0 = (op0[0] + op1[0] - dst[0]) / 2^9 and the second limb computes carry_limb_1 = (op0[1] + op1[1] - dst[1] + carry_limb_0) / 2^9 and so on until the last limb.
The division by 2^9 is done since op0[0] + op1[0] - dst[0] should either be 2^9 (if carry exists) or 0 (if carry doesn’t exist) and dividing it by 2^9 will result in a 1 or 0 value. Another thing to note is that in the implementation, we change the division by 2^9 to a multiplication by 2^22 which is the same thing in the M31 field since .
In addition, we also need to take into account the addition overflowing the 252-bit prime field (i.e. addition results in op0 + op1 = dst + P). To do this, we use another witness variable sub_p_bit, which is a 1-bit value that is subtracted only in the 3 limbs where has a non-zero limb. In this case, these are the limbs 0, 22, 27. Revisiting the computation for the first limb, we can see that it is now carry_limb_0 = (op0[0] + op1[0] - dst[0] - sub_p_bit) * 2^22.
A caveat of this approach is that subtracting by sub_p_bit can introduce an underflow, i.e. (op0[0] + op1[0] - dst[0] - sub_p_bit) * 2^22 = -1. This means that carry_limb_0 can also be -1, not just 0 or 1. Thus, we need to update the constraint for each carry to carry_limb_0 * (carry_limb_0 + 1) * (carry_limb_0 - 1) = 0.
Below are listed the findings found during the engagement. High severity findings can be seen as
so-called
"priority 0" issues that need fixing (potentially urgently). Medium severity findings are most often
serious
findings that have less impact (or are harder to exploit) than high-severity findings. Low severity
findings
are most often exploitable in contrived scenarios, if at all, but still warrant reflection. Findings
marked
as informational are general comments that did not fit any of the other criteria.