# Audit of the Stwo-Cairo Verifier
- **Client**: StarkWare
- **Date**: August 6th, 2025
- **Tags**: STARK, Cairo
## Introduction
On July 14th, 2025, StarkWare engaged zkSecurity to perform a three-week audit on the Stwo-Cairo verifier, which is a Cairo implementation of a verifier for the Stwo protocol.
### Scope
The audit focused on the `stwo_cairo_verifier` component in the [Stwo-Cairo repository](https://github.com/starkware-libs/stwo-cairo), at commit `aef7d09`.
The StarkWare team also provided us with a draft of the Stwo whitepaper, which we used as a reference for the theoretical background of the protocol.
### Summary and recommendations
Overall, we found the verifier code to be well written and organized. A caveat is that the Cairo verifier did not successfully compile at the time of audit. As a fallback, we could use a Rust implementation of the same verifier in `stwo_cairo_prover` to run end-to-end tests and proof-of-concepts.
Apart from the concrete [findings](#findings) listed at the end of this report, we have some strategic recommendations for keeping the code base secure in the longer term:
- **Validate prover-supplied data structures.** We found that the verifier accepts several data structures from the prover without proper validation, as documented in two findings ([1](#finding-high-unused-components-contribute-sum), [2](#finding-low-unvalidated-zip)). For example, zipping a verifier-validated array with a prover-provided one without validating lengths, or not checking that two different, related `Option` values provided by the prover are consistent. In general, the rule of thumb should be that whenever data from the proof is allowed to shape the verifier algorithm, it should be subject to some form of validation.
- **Be careful about hash collisions.** We identified multiple sources of hash collisions throughout the codebase, see [1](#finding-medium-hash-collisions), [2](#finding-info-hash-collisions-memory-section). While we found no direct exploits, these collisions complicate security analysis and could become exploitable in unexpected ways. We recommend to avoid hash collisions more consistently.
- **Keep consistency between the code and whitepaper.** During our audit, we discovered a few divergences between the core verifier implementation and the Stwo whitepaper. Divergences that are not directly exploitable were nonetheless recorded and reported as informational findings. Indeed, they are an indication that the deployed proof system may not fall directly under the security proof in the whitepaper. We recommend (re-)establishing consistency between the two.
- **Document overall Cairo AIR structure.** The Cairo AIR implements a sophisticated flat AIR architecture with multiple tables connected through LogUp arguments, with many interesting variations like opcodes tables, memory, builtins, chained rounds, etc. However, the overall structure, table variations and table relationships are not comprehensively documented, creating a barrier for newcomers to understand and review the code. We recommend creating high-level documentation of the complete AIR structure, including how the lookup relations ensure Cairo program execution correctness.
## Overview of Key Concepts
### Stwo, Cairo and `stwo-cairo`
Before diving into the report, it may be helpful for readers that we define and differentiate between "Stwo", "Cairo" and the repository being reviewed, `stwo-cairo`.
**Stwo**. "Stwo" refers to two things: a non-interactive STARK (_alt._ transparent SNARK) protocol and a Rust-based implementation of the protocol. The STARK is based on Circle STARK [[HLP24]](https://eprint.iacr.org/2024/278) and allows to prove the satisfaction of an AIR with additional features such as preprocessed and randomized columns. The protocol is described in an upcoming whitepaper which the Client has provided us with a draft version of. To avoid ambiguity throughout the report:
- we refer to Stwo, the non-interactive STARK protocol, as _the Stwo whitepaper_ or _the Stwo protocol_.
- we refer to Stwo, the Rust implementation of the Stwo protocol, as `stwo-rs`.
**Cairo**. As explained in the [Cairo documentation](https://www.cairo-lang.org/about-cairo/), "Cairo" is a tech stack that comprises multiple elements. Among them, we highlight:
- _CairoVM_, a virtual machine (VM) that is designed in such a way that its valid execution can be efficiently expressed as an AIR. This property is sometimes abbreviated as "SNARK-friendly" or "STARK-friendly".
- _Cairo_, a Rust-based high-level language that can be compiled to assembly code for the CairoVM.
We stay consistent with the terms defined in the Cairo documentation and will now use _Cairo_ and _CairoVM_ unambiguously and as above. We also define the _CairoAIR_ to be any (preprocessed and randomized) AIR that enforces the valid execution of the CairoVM.
**`stwo-cairo`**. As its name indicates, `stwo-cairo` is a combination of many of the above elements. The repository contains:
- the definition of a CairoAIR. This is in fact a particular type of AIR with preprocessed and randomized columns defined in the Stwo whitepaper as a _flat AIR_.
- a Rust-based prover that implements the Stwo protocol prover for the CairoAIR.
- a Cairo-based verifier, `stwo_cairo_verifier`, which implements the Stwo protocol verifier for the CairoAIR. This can be understood as the Cairo counterpart to the verifier in `stwo-rs`, specialized for the CairoAIR.
The latter component is the object of this audit. Writing a Cairo-based verifier for validity proofs of the CairoVM is of particular interest as it enables _recursive proof composition_. This technique is highly prevalent in high-performance SNARK/STARK stacks as it allows for proof aggregation (combining many proofs into one) and continuations (breaking up a large program's execution into multiple sub-proofs).
### The M31 Field and Extensions
Following the Stwo whitepaper, we write $\mathsf{M31} = \mathbb{F}_q$ to denote the finite field of order $$q = 2^{31}-1.$$
We assume that readers are familiar with the $\mathsf{M31}$ field, the _circle curve_ and _circle polynomials_ over a prime or extension field $F$. We direct the interested reader to our introductory material on these topics ([Part 1, Mersenne](https://blog.zksecurity.xyz/posts/circle-starks-1/), [Part 2, Circles](https://blog.zksecurity.xyz/posts/circle-starks-2/) and [Part 3, FFT](https://blog.zksecurity.xyz/posts/circle-starks-3/)).
**Secure extensions.** The field $\mathsf{M31}$ is too small to yield the desired security level for the Stwo protocol. To remediate this, the protocol samples challenges from a degree-$4$ extension of $\mathsf{M31}$. Once again following the Stwo whitepaper, we define the following extensions fields:
- the complex extension $\mathsf{CM31} = \mathbb{F}_{q^2}$ is constructed as $$\mathbb{F}_{q^2} = \mathbb{F}_{q}[\zeta]/(\zeta^2 + 1).$$ We write $i = \sqrt{-1}$ and express elements of $\mathsf{CM31}$ as $$z = a + i \cdot b, \quad a, b \in \mathsf{M31}.$$
- the quartic extension $\mathsf{QM31} = \mathbb{F}_{q^4}$ is constructed as $$\mathbb{F}_{q^4} = \mathbb{F}_{q^2}[\chi]/(\chi^2 - 2 - i).$$ We write $j = \sqrt{2 + i}$ and express elements of $\mathsf{QM31}$ as $$w= (a_0 + i \cdot b_0) + j \cdot (a_1 + i \cdot b_1), \quad a_0, a_1, b_0, b_1 \in \mathsf{M31}.$$
### The flat AIR
A _flat AIR_ is a collection of $\tau$ AIR tables, each with their own dimensions and constraints.
The tables are "connected" by enforcing the equality of partial rows _across tables_ via a lookup argument.
This setup provides a more flexible arithmetization than a classic monolithic AIR. Flat AIRs allow a ZKVM design to dedicate one table per gate, opcode or even full operations such as a hash function. By constraining operations in separate tables, flat AIRs ensure that each table is kept to the minimum number of columns required for its own set of constraints.
This approach is also referred to as a "multi-table STARK" or a "precompile-centric design", since the notion of dedicating a table to an operation first emerged with the idea of precompiles.
### Lookups between the tables
Stwo uses the _LogUp_ lookup argument to verify that every element in one sequence appears in another. Given two sequences $A$ and $B$, and letting $m(b)$ denote the multiplicity of $b$ in $A$, the argument relies on the identity:
$$
\sum_{a \in A} \frac{1}{X - a}
\;=
\;
\sum_{b \in B} \frac{m(b)}{X - b}.
$$
When $A$ and $B$ reside in different tables, the prover first commits to the vector of multiplicities $m$ (or, in some cases, they are hard-coded to particular constant values).
The verifier then samples a random point $\xi \in QM31$, and the prover provides commitments to the interaction columns along with the claimed sums:
$$
\begin{array}{rcl}
s_A &=& \sum_{a \in A} \frac{1}{\xi - a},\\
s_B &=& -\sum_{b \in B} \frac{m(b)}{\xi - b}.
\end{array}
$$
The verifier enforces AIR constraints on the original tables to confirm these sums and finally checks that $s_A + s_B = 0$.
To support lookups across multiple columns simultaneously, Stwo replaces each element by a random linear combination of the original columns.
For example, for column pairs $A = (A_1, A_2)$ and $B = (B_1, B_2)$, it tests:
$$
\sum_{(a_1,a_2)\in A} \frac{1}{X - (\alpha\,a_1 + a_2)}
\;=
\;
\sum_{(b_1,b_2)\in B} \frac{m(b_1,b_2)}{X - (\alpha\,b_1 + b_2)},
$$
at a random point $\xi$ and a random folding factor $\alpha$.
When handling several lookup relations, the verifier chooses independent challenges for each pair, aggregates all resulting sums, and checks that their total equals zero. For instance, with lookups $A\to B$ and $C\to D$, it verifies:
$$
\begin{align*}
&\sum_{a\in A}\frac{1}{X - a}
- \sum_{b\in B}\frac{m(b)}{X - b}\\
+ &\sum_{c\in C}\frac{1}{Y - c}
- \sum_{d\in D}\frac{m(d)}{Y - d}
= 0.
\end{align*}
$$
We note that soundness follows from applying the Schwartz–Zippel lemma in the multivariate setting, and is only guaranteed if challenges for each lookup pair are distinct.
### Circle Polynomials over QM31
Throughout the execution of the protocol, the verifier will be required to evaluate and apply constraints to circle polynomials over $\mathsf{QM31}$. These polynomials appear in the LogUp rounds, during the construction of the randomized columns of the components AIRs, and when running the univariate zero test on the composition polynomial.
In order to apply constraints to the LogUp polynomials, these must be added as columns to the component AIRs. However, all AIRs are defined over $\mathsf{M31}$ and columns cannot contain elements of $\mathsf{QM31}$.
This tension is resolved by representing a single circle polynomial over $\mathsf{QM31}$ $P$ as four circle polynomials $p_0, \dots, p_3$ over $\mathsf{M31}$ with the following joining rule $$P = (p_0 + i \cdot p_1) + j \cdot (p_2 + i \cdot p_3).$$
In addition to solving the tension mentioned above, this method of polynomial representation greatly simplifies the verifier's logic. Every polynomial received by the verifier is now a circle polynomial over $\mathsf{M31}$, avoiding the need for (and pitfalls of) managing oracles over different alphabets.
### Multi-vector Commitment Scheme from Merkle Trees
Protocols for AIR satisfiability usually require to commit to each of the columns in the AIR table. A common optimization, as detailed [here](https://zksecurity.github.io/RFCs/rfcs/starknet/merkle.html), consists in committing the whole table in a single Merkle tree, where the $i$-th leaf node contains the values of all the columns at row $i$.
Stwo applies a similar optimization to its flat AIR arithmetization. However, a flat AIR is composed of multiple tables with _different column lengths_. Naively committing to a flat AIR would result in producing one Merkle root per table.
To avoid this, Stwo uses modified Merkle trees that allow internal tree nodes to also carry data. We give an illustrated example below constructing a tree of depth $3$ that commits to three vectors, two of length $8$ and one of length $4$.
### Circle FRI
Like univariate FRI, the Circle FRI protocol tests whether a committed function is close to a Reed–Solomon codeword.
However, instead of operating on a univariate polynomial, the committed function is defined over a circle domain in $\mathsf{QM31}$.
The protocol iteratively reduces the domain size by folding the function into its even and odd parts until the domain is small enough for direct testing. In Circle FRI, this folding is achieved using two 2-to-1 maps:
- point doubling, which sends a circle group element to its double (denoted $\pi$), and
- x-axis projection, which maps a circle group element to its x-coordinate (denoted $\pi_x$).
Crucially, the x-coordinate of the doubled point can be computed without the y-coordinate.
Therefore, we first apply the x-axis projection and then iteratively apply point doubling.
This process is illustrated in the following diagram.
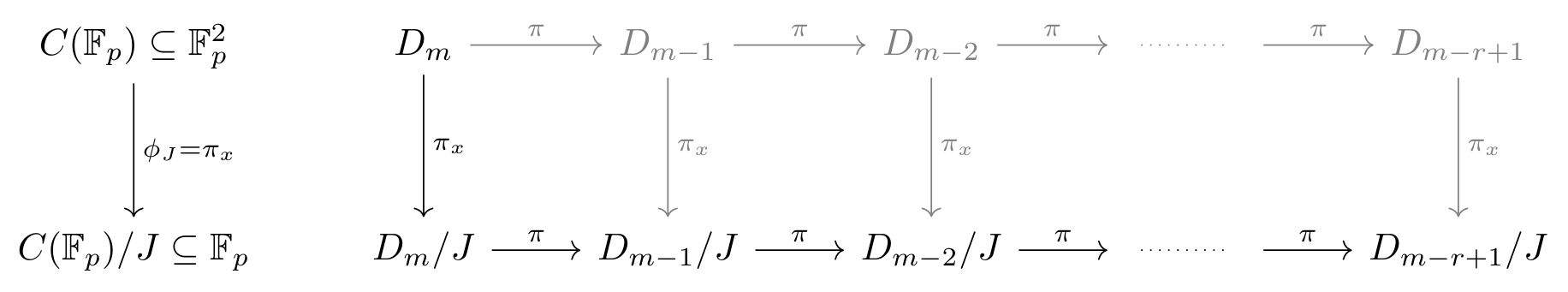
We also note that the x-axis projection maps each point to its x-coordinate, flattening the domain for folding to a line.
### Pipelining Circle FRI
Another consequence of the flat AIR arithmetization is that the proof system now requires to run a batched proximity test for many vectors of different sizes. Padding all vectors to the size of the largest vector would undermine some of the savings provided by the flat AIR. Instead, Stwo implements an optimization that is also present in plonky2/3 and is referred to as _pipelining_.
The idea stems from the observation that FRI naturally produces domains and vectors of decreasing sizes during the commit phase. Rather than padding all vectors to the size of the largest domain, a pipelined implementation of FRI batches vectors _at their corresponding step of the FRI commit phase_.
Consider the following example: testing proximity of vectors $v_0$ and $v_1$ to a Reed-Solomon code, where $|v_1| = |v_0|/2$. Following the folding procedure, the prover computes the even and odd components of $v_0$ which we will denote $v_{0, e}$ and $v_{0, o}$ respectively. In the classic FRI protocol, the prover is given a verifier challenge $\alpha$ and would send the oracle $f_1 = v_{0, e} + \alpha \cdot v_{0, o}$. However, in a pipelined implementation, we take advantage of the fact that $|v_{0, e}| = |v_{0, o}| = |v_1|$ and instead compute:
$$
f_1 = v_{0, e} + \alpha \cdot v_{0, o} {\color{blue} + \alpha^2 \cdot v_1.}
$$
The rest of the protocol proceeds as normal, unless there are smaller vectors that need to be inserted.
The above example is shown with regular polynomials. Working with circle polynomials introduces small complications which are explained and dealt with in the Stwo whitepaper. We also note that, to the best of our knowledge, the Stwo whitepaper is the first resource that proves the soundness of this batching method.
### Proving polynomial evaluations using FRI
In STARKs, the FRI protocol can be turned into an evaluation proof via a standard quotienting technique.
The verifier first receives an oracle for the original polynomial $p(x)$ as a vector of evaluations in $\mathsf{M31}$.
Next, they sample a random out-of-domain circle point $Q \in C(\mathsf{QM31}) \backslash C(\mathsf{CM31})$ and request the evaluation $p(Q)$.
The prover sends the purported value $V$, and then both prover and verifier engage in a low-degree test using FRI on the quotient:
$$
p'(x) = \frac{p(x) - L_{Q,V}(x)}{V_Q(x)}.
$$
Here, $L_{Q,V}(x)$ is the unique linear polynomial interpolating $(Q,V)$ and $(\overline{Q},\overline{V})$, while $V_Q(x)$ vanishes at $Q$ and $\overline{Q}$.
The notation $\overline{Q}$ denotes the complex conjugate of $Q$ in $\mathsf{QM31}$ in the second extension.
We note that this works because for any polynomial $p(x)$ over the base field $\mathsf{M31}$, we have $p(\overline{Q}) = \overline{p(Q)}$.
As in the univariate case, if $p'(x)$ is a low-degree polynomial rather than a rational function, the verifier is convinced that the evaluation claim is correct, i.e., that $p(Q)=V$.
### FRI and Pipelining in Stwo-Cairo
In Stwo-Cairo, folding is handled by the `fri` component.
During the commit phase, the prover repeatedly commits to oracle polynomials while the verifier issues a folding challenge $\alpha$ at each step.
After the final round, the prover reveals the last polynomial in the clear.
In the decommitment phase, the verifier selects query positions in the initial layer and requests the corresponding evaluations from the prover.
For each step, the verifier also checks the Merkle authentication paths for the queried evaluations.
It then uses these values to iteratively fold and compute the expected evaluations at each successive layer.
At the end, the verifier obtains queries and expected evaluations for the final polynomial, which it verifies by direct evaluation at those points.
To support pipelining, the verifier applies an x-axis projection to _all_ committed columns before performing a pipelined folding of those columns using the point-doubling map.
### CairoAIR
CairoAIR is an AIR that proves that a Cairo program was executed correctly (i.e. according to the semantics of the CairoVM).
#### CairoVM
To give a brief introduction to CairoVM, the CairoVM contains a read-only memory and a CPU with 3 registers (`pc`, `ap`, `fp`) that executes a single Cairo instruction every step. As can be seen in the figure below, a Cairo instruction is composed of 64 bits, where the first 3 16-bits represent the offsets to the 3 operands (`dst`, `op0`, `op1`) that the instruction uses.

The next 15 bits are flags which determine which of the registers to use for the operands and how the 3 registers should be updated after execution. It also determines which opcode to use for the instruction, where each unique opcode defines a custom logic for the instruction. Every Cairo instruction is mapped to a specific opcode, which can range from basic computation (e.g. `ADD` or `MUL` opcodes) to programming language specific ones (e.g. `CALL`, `RET`). CairoAIR extends the functionality of a Cairo instruction defined in the Cairo paper to define custom opcodes using an `opcode_extension` field. Essentially, a Cairo instruction is expanded to 72 bits and the last 9 bits (64 to 72) are allocated for the `opcode_extension` field. Currently, the following opcode extension values are supported:
- `0`: Stone, which are the original opcodes defined in the Cairo paper
- `1`: Blake
- `2`: BlakeFinalize
- `3`: QM31Operation
#### The AIR
We now give a simplified version of how the CairoAIR proves that the correct execution of a Cairo program.
The verifier is given only the following values:
- The initial and final values of the 3 registers (`pc`, `ap`, `fp`)
- The Cairo program, which is a set of Cairo instructions
and the prover needs to prove the following:
1. Each Cairo instruction was executed correctly according to the CairoVM semantics
2. The Cairo program was executed on the initial register values and resulted in the final register values
3. The memory values accessed during the execution of the Cairo program do not violate the read-only memory model
The CairoAIR implements these checks using a flat AIR (i.e. multiple tables that are connected to each other using lookups). Below is a simplified diagram of what the CairoAIR looks like.
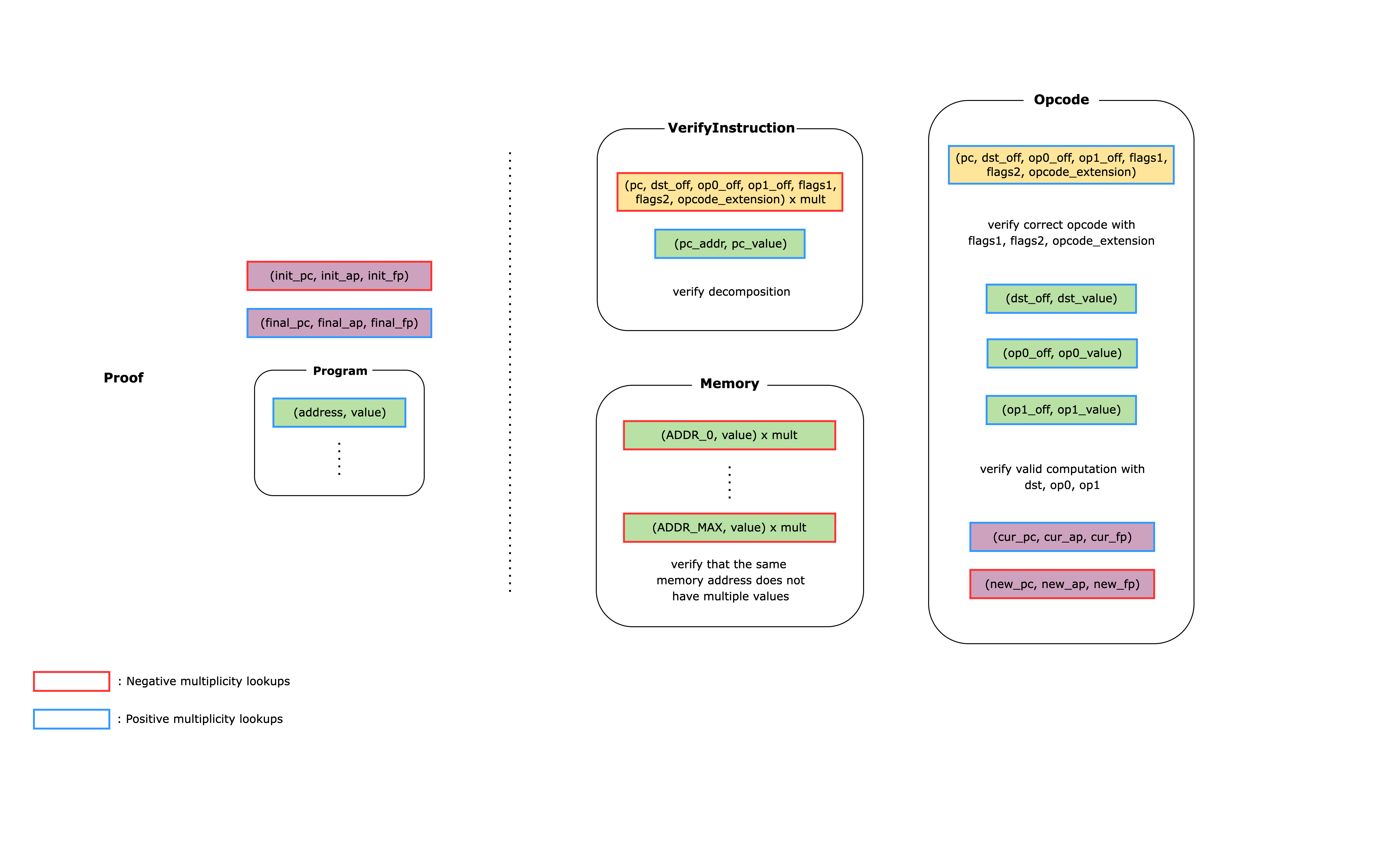
The rounded rectangles on the right-hand side of the diagram each represent a unique table that the prover constructs as part of the witness. The left-hand side shows the public values that are given to the verifier: the initial and final values of the 3 registers and the Cairo program. Each non-rounded rectangle represents a lookup relation where red edges means a lookup relation with a negative multiplicity and blue edges mean a lookup relation with a positive multiplicity. Each non-rounded rectangle with the same fill colors represent lookup relations that are connected to each other. When verifying the proof, the verifier can simply check that the total sum of the values in all the non-rounded rectangles is equal to zero.
We now show how this AIR can prove what the bullet points mentioned above:
1. To determine which opcode to use for the instruction, we need to first read the instruction from memory using the `pc` register value and decompose it into offsets and flags. Reading the instruction and decomposing it is done inside the `VerifyInstruction` table and the result is looked up by the `Opcode` table using the `(pc, dst_off, op0_off, op1_off, flags1, flags2, opcode_extension)` relation. Then, using the offsets and the flags, we read the values of the operands from the `Memory` table using the `(dst_off, dst_value)`, `(op0_off, op0_value)`, and `(op1_off, op1_value)` relations. Finally, we check that the computation for the corresponding opcode is done correctly using the constraints in the `Opcode` table.
2. The `Opcode` table also updates the register values according to the flags in the instruction. This means that if we lookup the input register values for an instruction as positive and the output register values for the same instruction as negative, when adding all the lookup relations together, everything will cancel out except for the input to the first instruction and the output of the last instruction. Since these register values are public to the verifier, the verifier can simply subtract `(init_pc, init_ap, init_fp)` and add `(final_pc, final_ap, final_fp)` to the total claimed sum and check that it equals zero.
3. To check the validity of the read-only memory, we need to check that each memory address does not map to multiple values. To do this, the `Memory` table makes sure that only one row can be defined per address. Whenever we need to access a value in memory, we add a `(addr, value)` relation, while the `Memory` table subtracts the same relation. Since there can be multiple accesses to the same memory address, the `Memory` table also has a `multiplicity` column that is used to multiply the `(addr, value)` relation. Note that in the actual `stwo-cairo` code, the memory address is first mapped to an id and then the id is mapped to the value, but we omit this for brevity.
### The `AddOpcode` table
To give an example of how an Opcode table is implemented, we give an overview of the `AddOpcode` table.
As we saw in [the previous section](#the-air), an `Opcode` table does the following:
1. uses the `VerifyInstruction` table to decompose the instruction into offsets and flags.
2. verifies that the instruction corresponds to the current opcode using the flags.
3. uses the `Memory` table to get the values of the operands `op0`, `op1`, and `dst`.
4. verifies that the opcode operation is done correctly.
5. updates the 3 register values (`pc`, `ap`, `fp`) using the flags.
In this section, we go over how the `AddOpcode` table implements step 4 since the other steps are general for all Opcode tables and were already covered.
Assuming that the operands `op0`, `op1`, and `dst` are correctly accessed from the `Memory` table, the main constraint of the `AddOpcode` table is to check that `op0 + op1 = dst`. But before diving deeper into the constraints, we need to understand that Cairo and Stwo use different fields and thus we need to convert between them. Cairo works over the 252-bit prime field $P = 2^{251} + 17 \cdot 2^{192} + 1$, while Stwo works over the 31-bit prime field $M31 = 2^{31} - 1$. CairoAIR decomposes the 252-bit integers into 28 9-bit limbs and range checks that each limb is in the range $[0, 2^9)$.
To check that the two sets of limbs are correctly added, we iterate from the least significant limb to the most significant limb. For each limb except for the first, we also need to take into account the carry from the previous limb. This check of additions over multiple limbs is done over a single constraint as there is no multiplication involved and we don't need to worry about the degree of the constraint. For example, the first limb computes `carry_limb_0 = (op0[0] + op1[0] - dst[0]) / 2^9` and the second limb computes `carry_limb_1 = (op0[1] + op1[1] - dst[1] + carry_limb_0) / 2^9` and so on until the last limb.
The division by `2^9` is done since `op0[0] + op1[0] - dst[0]` should either be `2^9` (if carry exists) or `0` (if carry doesn't exist) and dividing it by `2^9` will result in a `1` or `0` value. Another thing to note is that in the implementation, we change the division by `2^9` to a multiplication by `2^22` which is the same thing in the M31 field since $2^9 \cdot 2^{22} = 2^{31} = 1 \bmod{M31}$.
In addition, we also need to take into account the addition overflowing the 252-bit prime field $P$ (i.e. addition results in `op0 + op1 = dst + P`). To do this, we use another witness variable `sub_p_bit`, which is a 1-bit value that is subtracted only in the 3 limbs where $P$ has a non-zero limb. In this case, these are the limbs `0`, `22`, `27`. Revisiting the computation for the first limb, we can see that it is now `carry_limb_0 = (op0[0] + op1[0] - dst[0] - sub_p_bit) * 2^22`.
A caveat of this approach is that subtracting by `sub_p_bit` can introduce an underflow, i.e. `(op0[0] + op1[0] - dst[0] - sub_p_bit) * 2^22 = -1`. This means that `carry_limb_0` can also be `-1`, not just `0` or `1`. Thus, we need to update the constraint for each carry to `carry_limb_0 * (carry_limb_0 + 1) * (carry_limb_0 - 1) = 0`.
## Findings
### Public Memory ID Values Missing from Fiat-Shamir Transcript, Allowing Proof Forgery
- **Severity**: High
- **Location**: channel/{poseidon252, blake2s}.cairo
**Description**.
Before drawing the interaction challenges, all the public claims about the execution trace are mixed in the Fiat-Shamir channel.
This includes, in particular, all the public memory claims.
```rust
fn mix_into(self: @PublicMemory, ref channel: Channel) {
let PublicMemory { program, public_segments, output, safe_call } = self;
// Program is the bootloader and doesn't need to be mixed into the channel.
let _ = program;
// Mix public segments.
public_segments.mix_into(ref channel);
// Mix output memory section.
channel.mix_memory_section(output);
// Mix safe_call memory section.
channel.mix_u64(safe_call.len().into());
for (id, value) in safe_call.span() {
channel.mix_u64((*id).into());
// Mix each element of the array individually
for val_element in (*value).span() {
channel.mix_u64((*val_element).into());
}
}
}
```
Focusing on the `output` claim, it is a vector of pairs `(memory_id, value)`.
The `mix_memory_section` function mixes the memory ID values into the channel, but it does not mix the memory ID keys: notice how the first component of the pair is ignored in the following code.
```rust
fn mix_memory_section(ref self: Poseidon252Channel, data: @Array<(u32, [u32; 8])>) {
// TODO(Gali): Make this more efficient.
let mut flat_data = array![];
for entry in data.span() {
let (_, val) = entry;
flat_data.append_span((*val).span());
}
self.mix_u32s(flat_data.span());
}
```
Later, interaction challenges are drawn from the challenge, and all the public memory claims are transformed into a vector of triples `(address, memory_id, value)` and are added into the LogUp sum.
In particular, for the `output` claim, each pair `(memory_id, value)` is transformed into triples `(final_ap + i, memory_id, value)`.
```rust
fn get_entries(
self: @PublicMemory, initial_pc: u32, initial_ap: u32, final_ap: u32,
) -> Array {
let mut entries = array![];
// [...]
// Output.
i = 0;
for (id, value) in self.output.span() {
entries.append((final_ap + i, *id, *value));
i += 1;
}
// [...]
entries
}
```
Then, for each triple `(address, memory_id, value)`, the following LogUp sum is computed.
```rust
for entry in self
.public_memory
.get_entries(
initial_pc: (*self.initial_state.pc).into(),
initial_ap: (*self.initial_state.ap).into(),
final_ap: (*self.final_state.ap).into(),
)
.span() {
let (addr, id, val) = *entry;
let addr_m31 = addr.try_into().unwrap();
let id_m31 = id.try_into().unwrap();
let addr_to_id = lookup_elements
.memory_address_to_id
.combine([addr_m31, id_m31])
.inverse();
// Use handwritten implementation of combine_id_to_value to improve performance.
let alpha = *lookup_elements.memory_id_to_value.alpha;
let mut combine_sum = combine::combine_felt252(val, alpha);
combine_sum = combine_sum * alpha
+ id_m31.into()
- *lookup_elements.memory_id_to_value.z;
let id_to_value = combine_sum.inverse();
sum += addr_to_id + id_to_value;
}
```
This sum roughly corresponds to the following equation:
$$
\begin{align*}
& \frac{1}{\alpha \cdot \text{addr}_1 + \text{id}_1 - z_1} + \frac{1}{\sum _{i=1}^n \left( \beta^i \cdot \text{value}_{1, i}\right) + \text{id}_1 - z_2} \\
+& \frac{1}{\alpha \cdot \text{addr}_2 + \text{id}_2 - z_1} + \frac{1}{\sum _{i=1}^n \left( \beta^i \cdot \text{value}_{2, i}\right) + \text{id}_2 - z_2} + \dots
\end{align*}
$$
where $\alpha$, $\beta$ and $z$ are challenges drawn from QM31.
Our observation is that, in particular in the case of the `output` claim, the memory ID values are not mixed into the Fiat-Shamir channel, and thus can be changed by a malicious prover **after** knowing the interaction challenges, and in particular after knowing the values of $\alpha$, $\beta$ and $z$.
**Impact**.
Since the memory ID values are not mixed into the Fiat-Shamir channel, the potential impact is that a malicious prover can manipulate the LogUp sum to be zero, even if the lookup relations are not satisfied.
For the purposes of the attack, all `address` and `values` can be considered "fixed", as they are included in the Fiat-Shamir channel before the interaction challenges are drawn.
This means that the attacker succeeds in forging a proof if they can find values $\text{id}_1, \text{id}_2, \dots, \text{id}_k$ such that the following equation holds:
$$
\begin{align*}
& \frac{1}{\text{id}_1 + \gamma_1} + \frac{1}{\text{id}_1 + \chi_1} \\
+& \frac{1}{\text{id}_2 + \gamma_2} + \frac{1}{\text{id}_2 + \chi_2} + \dots \\
+& \frac{1}{\text{id}_k + \gamma_k} + \frac{1}{\text{id}_k + \chi_k} = c
\end{align*}
$$
where $\gamma_i$ and $\chi_i$ are constants over QM31 which can be computed after drawing the challenges, and $c$ is a target sum value also over QM31.
The interesting part is that the values $\text{id}_1, \text{id}_2, \dots, \text{id}_k$ have to be from the base field M31, which makes this equation non-trivial to solve.
Therefore, intuitively for a solution to exist, the number of memory IDs $k$ must be at least $4$ to cover the degrees of freedom of the equation.
We provide one generic attack strategy, which can be used to solve this equation: the idea is to use a generic birthday paradox attack to find a $k$-sum.
This attack is based on the Wagner's attack described in [this paper](https://www.iacr.org/archive/crypto2002/24420288/24420288.pdf).
- The attacker precomputes lists of values $1/(\text{id}_i + \gamma_i) + 1/(\text{id}_i + \chi_i)$ for all $i$. Since the values $\gamma_i$ and $\chi_i$ are effectively random, the list values can be thought as random.
- Now, the attacker needs to find values in those lists that sum to $c$, which is exactly an instance of the $k$-sum problem.
Interestingly, for a $4$-sum problem, the Wagner's attack can be used to find a solution in $O(2^{n/3})$ time, where $n$ is the number of bits of the challenge space.
In this case, the work required is roughly $2^{41}$.
However, we conjecture that if we increase $k$ to be $2^{10}$, then the cost of the attack is reduced to approximately $2^{22}$, which is feasible on a modern computer.
As a final remark, this particular attack is completely generic, and we believe that more efficient attacks may exist, e.g., based on solving the equation directly using Groebner bases or other algebraic techniques.
**Recommendation**.
We recommend to mix the memory ID values into the Fiat-Shamir channel, so that they cannot be manipulated after the interaction challenges are drawn.
### Prover Can Manipulate LogUp Relations Because Unused Components Are Not Excluded from the Sum
- **Severity**: High
- **Location**: cairo_air/src/lib.cairo
**Description**. Several components of the Cairo AIR are optional. Whether or not the verifier adds those components is determined by the `CairoClaim` that is part of a `Cairo` proof:
```rust
pub struct CairoProof {
pub claim: CairoClaim,
pub interaction_pow: u64,
pub interaction_claim: CairoInteractionClaim,
pub stark_proof: StarkProof,
}
```
For example, `claim.blake_context.claim` is of type `Option`, and if the option is `None`, the Blake components are not added; which means the verifier will not include the components' constraints in the composition polynomial.
```rust
impl BlakeContextComponentsImpl of BlakeContextComponentsTrait {
fn new(
claim: @BlakeContextClaim,
interaction_elements: @CairoInteractionElements,
interaction_claim: @BlakeContextInteractionClaim,
) -> BlakeContextComponents {
if let Some(claim) = claim.claim {
BlakeContextComponents {
components: Some(
BlakeComponentsImpl::new(
claim,
interaction_elements,
interaction_claim.interaction_claim.as_snap().unwrap(),
),
),
}
} else {
BlakeContextComponents { components: None }
}
}
```
A `CairoProof` also holds a `CairoInteractionClaim` that contains the claimed LogUp sums of all components, and similarly contains options for sums of optional components. If the claimed sum of an optional component is present, it is added to the overall LogUp sum:
```rust
pub fn lookup_sum(
claim: @CairoClaim,
elements: @CairoInteractionElements,
interaction_claim: @CairoInteractionClaim,
) -> QM31 {
// ...
sum += interaction_claim.blake_context.sum();
// ...
}
// ...
impl BlakeContextInteractionClaimImpl of BlakeContextInteractionClaimTrait {
// ...
fn sum(self: @BlakeContextInteractionClaim) -> QM31 {
if let Some(interaction_claim) = self.interaction_claim {
interaction_claim.sum()
} else {
Zero::zero()
}
}
}
```
The issue is that the verifier never checks that optionality of components and their corresponding sums is consistent with each other. Specifically, the prover can set the Blake interaction claim to `Some(value)` **even if the Blake claim is `None`**. In that case, the interaction claim is added to the overall sum but is not constrained in any way, because the components that would normally constrain it are missing. That makes it easy for the prover to manipulate the total LogUp sum.
Almost all optional components are affected by this issue:
- Pedersen
- Poseidon
- Blake
- Opcodes
- all builtins
The case of Pedersen, Poseidon, and builtins is similar to Blake, where options for claim and interaction claim are not checked to be consistent.
For opcode components, the proof contains a vector of claims, which leads to a vector of components to be added, and similarly there's a vector of interaction claims. However, the lengths of claims and interactions claims are not checked to be equal, so the prover can add extra unconstrained terms to the LogUp sum by appending them to the interaction claims vector.
The only optional components _not_ vulnerable are the `memory_id_to_value` components, that also come with vectors of claims and interaction claims. In this case, the issue is prevented by the following consistency check (in `CairoAirNewImpl::new()`):
```rust
assert!(
cairo_claim
.memory_id_to_value
.big_log_sizes
.len() == interaction_claim
.memory_id_to_value
.big_claimed_sums
.len(),
);
```
**Impact**. The issue enables attackers to forge proofs that are invalid in a number of ways.
As a proof-of-concept, we modify the `prove_cairo()` function to generate a valid proof for an incorrect output claim of the example Cairo program included in the repository.
The modified prover performs the following operations:
- It arbitrarily changes the first output value claim.
- It computes the interaction challenges, and then compute the original LogUp sum, which will not be zero.
- At this point, it adds a `claimed_sum` value in an unused interaction claim set to exactly the negative of the modified LogUp sum, so that the final LogUp sum is zero.
In the end, verification passes thanks to the zero LogUp sum, despite the incorrect output claim.
```diff
pub fn prove_cairo(
input: ProverInput,
pcs_config: PcsConfig,
preprocessed_trace: PreProcessedTraceVariant,
) -> Result, ProvingError>
where
SimdBackend: BackendForChannel,
{
// [...]
// Run Cairo.
let cairo_claim_generator = CairoClaimGenerator::new(input);
// Base trace.
let mut tree_builder = commitment_scheme.tree_builder();
let span = span!(Level::INFO, "Base trace").entered();
- let (claim, interaction_generator) = cairo_claim_generator.write_trace(&mut tree_builder);
+ let (mut claim, interaction_generator) = cairo_claim_generator.write_trace(&mut tree_builder);
span.exit();
+
+ // Modify the first output value claim to be another value, e.g., 0x41.
+ claim.public_data.public_memory.output[0].1 = [0x41, 0, 0, 0, 0, 0, 0, 0];
claim.mix_into(channel);
// [...]
- let interaction_claim =
+ let mut interaction_claim =
interaction_generator.write_interaction_trace(&mut tree_builder, &interaction_elements);
+
+ // since we modified an output claim, the lookup sum will not be zero
+ let modified_lookup_sum = lookup_sum(&claim, &interaction_elements, &interaction_claim);
+ println!(
+ "Modified lookup sum: {}",
+ modified_lookup_sum.to_string()
+ );
+
+ // Add an unused claimed sum to make it zero.
+ // In this specific case, the add_mod_builtin is null in the
+ // original proof.
+ interaction_claim.builtins.add_mod_builtin = Some(InteractionClaim {
+ claimed_sum: -modified_lookup_sum
+ });
// [...]
// Validate lookup argument.
debug_assert_eq!(
lookup_sum(&claim, &interaction_elements, &interaction_claim),
SecureField::zero()
);
interaction_claim.mix_into(channel);
tree_builder.commit(channel);
// [...]
Ok(CairoProof {
claim,
interaction_pow,
interaction_claim,
stark_proof: proof,
})
}
```
The output of the prover is the following:
```txt
Modified lookup sum: (704398217 + 987329512i) + (1683849168 + 1389614104i)u
New lookup sum: (0 + 0i) + (0 + 0i)u
```
and the modified proof is accepted by the verifier.
**Recommendation**. Add consistency checks for all optional components, which guarantee that if a component is not used, its LogUp sum contribution is zero.
### Hash Collisions Due To Zero-Padding and Flexible Data Structures
- **Severity**: Medium
- **Location**: cairo_air, verifier_core
**Description**. Some instances of hashes in the code base exhibit collisions due to zero padding. For example, `hash_node()` in `poseidon_hasher.cairo`:
```rust
if !column_values.is_empty() {
let mut word = (*column_values.pop_front().unwrap_or(@BaseField { inner: 0 }))
.inner
.into();
for _ in 1..M31_ELEMENTS_IN_HASH {
let v = (*column_values.pop_front().unwrap_or(@BaseField { inner: 0 }))
.inner
.into();
word = word * M31_SHIFT + v;
}
hash_array.append(word);
}
```
Note that zeros replace any elements missing to make the input length a multiple of `M31_ELEMENTS_IN_HASH = 8`. In particular, inputs like `[1]` and `[1,0]` and `[1,0,0]` will all yield the same hash value.
This particular zero-extension collision was fixed in a commit shortly after the audit freeze, but another collision is still present in the same function : The special case where there are no child nodes and exactly 4 column values `[v0, v1, v2, v3]` seems to collide with the case of 8 column values `[v0, v1, v2, v3, 0, 0, 0, 0]`.
A similar zero-extension collision happens in `mix_u32s()` in the Poseidon channel implementation, where input u32s are zero-padded up to a multiple of 7. In current usage of `mix_u32s()`, this should not present an issue.
A slightly different type of hash collision is prevalent throughout `cairo_air/src/lib.cairo`: Collisions due to flexible data structures, where only the _content_ but not the exact structure serves as hash input. For example, this is how the `PublicSegmentRanges` are mixed into the channel:
```rust
impl PublicSegmentRangesImpl of PublicSegmentRangesTrait {
fn mix_into(self: @PublicSegmentRanges, ref channel: Channel) {
for segment in self.present_segments() {
segment.mix_into(ref channel);
}
}
```
The return value of `present_segments()` is some sublist of 11 different public memory segments, 10 of which are optional. The hash cannot distinguish _which_ of the segments are present.
Similarly, when optional claims are mixed into the channel, it looks like this:
```rust
impl BuiltinsClaimImpl of BuiltinsClaimTrait {
fn mix_into(self: @BuiltinsClaim, ref channel: Channel) {
if let Some(claim) = self.add_mod_builtin {
claim.mix_into(ref channel);
}
if let Some(claim) = self.bitwise_builtin {
claim.mix_into(ref channel);
}
if let Some(claim) = self.mul_mod_builtin {
claim.mix_into(ref channel);
}
// ...
```
There are hash collisions because, for example, values of `self.add_mod_builtin = Some(X)` and `self.bitwise_builtin = None` yield the same hash as `self.add_mod_builtin = None` and `self.bitwise_builtin = Some(X)`.
Other optional claims like `BlakeContextClaim`, `PoseidonContextClaim` and `memory_id_to_big::Claim` have the same issue. On the other hand, `OpcodeClaim` avoids the issue by mixing the length of vectors into the channel together with their content.
**Impact and recommendation**. We did not find a way to exploit any of the hash collisions found. However, given how prevalent these collisions are and how they could interact in complex ways, we believe it would be safer to remove them. In general, this is easily accomplished by hashing an indicator of the data structure along with the data itself, such as the length of an input array or a bit in the case of an option.
### Bias in Challenge Derivation Can Reduce Security Level
- **Severity**: Low
- **Location**: channel/poseidon252.cairo
**Description**. In the Poseidon channel implementation, `draw_base_felts()` first draws a felt252 and from that extracts 8 M31 elements:
```rust
fn draw_base_felts(ref channel: Poseidon252Channel) -> [M31; FELTS_PER_HASH] {
let mut cur: u256 = draw_secure_felt252(ref channel).into();
[
extract_m31(ref cur), extract_m31(ref cur), extract_m31(ref cur), extract_m31(ref cur),
extract_m31(ref cur), extract_m31(ref cur), extract_m31(ref cur), extract_m31(ref cur),
]
}
// ...
fn extract_m31(ref num: u256) -> M31 {
let (q, r) = DivRem::div_rem(num, M31_SHIFT_NZ_U256);
num = q;
M31Trait::reduce_u128(r.low)
}
```
`extract_m31()` works by
- extracting the first 31 bits of the input: `div_rem()` by `M31_SHIFT_NZ_U256`$= 2^{31}$ in the code above, and
- reducing the result modulo the M31 field; this happens inside `reduce_u128()`.
Since $(2^{31} - 1)\bmod \text{M31} = 0$ while $x \bmod \text{M31} = x$ for all other 31-bit strings, this operation introduces a bias: Drawing 0 is twice as likely as drawing any other M31 element.
**Impact**. The chance for the prover to draw a zero base felt is $2^{-30}$ instead of the ideal $2^{-31}$. When drawing a QM31 extension field element, which uses the first 4 outputs of `draw_base_felts()`, the chance of drawing an overall zero is $2^{-120}$ instead of $2^{-124}$. Drawing 0 for a challenge in any place likely lets an attacker forge an invalid proof, so the bias reduces the maximum security level that Stwo can target, by 4 bits.
**Recommendation**. The blake2s channel implementation already handles the bias correctly by rejecting samples that fall outside a multiple of the M31 range. We recommend to do the same for Poseidon.
### Rust Verifier Misses Check of Preprocessed Root
- **Severity**: Low
- **Location**: stwo_cairo_prover/crates/cairo-air/src/verifier.rs
**Description**. In the Cairo version of `verify_cairo()`, the validity of preprocessed traces is checked by comparing the preprocessed root to a hard-coded value (which depends on the blowup factor).
```rust
// Preprocessed trace.
let expected_preprocessed_root = preprocessed_root(pcs_config.fri_config.log_blowup_factor);
let preprocessed_root = stark_proof.commitment_scheme_proof.commitments[0].clone();
assert!(preprocessed_root == expected_preprocessed_root);
```
The same check is missing from the Rust version of `verify_cairo()`.
**Impact**. The values in preprocessed traces are not determined by polynomial constraints, but hard-coded to specific values. A check like the above is therefore essential, otherwise the prover can set the values in preprocessed traces arbitrarily.
The issue is only marked with low severity because the Rust verifier was outside the audit scope and we are told it is mainly intended for debugging.
**Recommendation**. Add the missing check in the Rust verifier.
### Zipping with Prover Input Could Cause Skipped Merkle Verification
- **Severity**: Low
- **Location**: pcs/verifier.cairo
**Description**. In `verify_values()`, the implementation zips `self.trees` (an array of length 4, created by the verifier) with `queried_values` which is taken from the proof. If the prover supplies `queried_values` shorter than `self.trees`, `zip()` will only iterate up to the shorter length. This causes the verifier to skip `tree.verify()` on some of the trees, which is one of the core checks in the protocol.
```rust
for (tree, queried_values) in self.trees.span().into_iter().zip(queried_values.span()) {
let decommitment = decommitments.next().unwrap();
// The Merkle implementation pops values from the query position dict so it has to
// be duplicated.
let query_positions = query_positions_by_log_size.clone_subset(unique_column_log_sizes);
tree.verify(query_positions, *queried_values, decommitment);
}
```
**Impact**. There is no concrete impact, because insufficient numbers of trees in `queried_values` will later cause `queried_values_at_row` in `accumulate_row_quotients()` to be shorter than expected, and cause an array out-of-bounds error. This can't be circumvented by the prover, so it is not possible to get the verifier to succeed after skipping Merkle opening checks.
However, this failure seems coincidental and could be accidentally removed by refactoring `accumulate_row_quotients()`, in which case the skipped checks would be catastrophic.
**Recommendation**. In general, data from the proof should be validated before it is allowed to structure the verifier algorithm. In the case of `zip()`, we recommend to assert that the lengths of the zipped arrays are equal.
```rust
assert!(self.trees.len() == queried_values.len());
for (tree, queried_values) in self.trees.span().into_iter().zip(queried_values.span()) {
// ...
```
### IOP and Soundness Proof in Stwo Whitepaper Incorrectly Handle Vector Lookups of Heterogeneous Dimension
- **Severity**: Low
- **Location**: Stwo_Whitepaper.pdf
**Description**. The Stwo whitepaper features the concept of a channel $\mathcal{L}$ that captures communication between AIR tables: Each gate/table can _use_ a number of elements from the channel, as well as _yield_ other elements to the channel:
$$\vec{w}_{i,0}, \ldots, \vec{w}_{i,r} \leftarrow \mathcal{L},$$
$$\vec{z}_{i,0}, \ldots, \vec{z}_{i,s} \rightarrow \mathcal{L}.$$
The paper allows each of these vectors to be of its own dimension.
The flat AIR relation requires that the set of all used elements, from all tables, is contained in the set of all yielded elements:
$$
\bigcup_{i,j,t} \{ \vec{w}_{i,j,t} \} \subseteq \bigcup_{i,j,t} \{ \vec{z}_{i,j,t} \}.
$$
Note that here we are potentially trying to equate vectors of different dimension.
In the IOP, vectors $(z_0,\ldots,z_{n-1})$ are reduced to scalars by summing over elements times powers of a challenge, $z_0 + \alpha z_1 + \ldots + \alpha^{n-1} z_{n-1}$.
These scalars participate in a shared LogUp protocol.
The problem is that vectors of different dimensions can interact in the LogUp sum if one of them has trailing zeros, e.g. a vector $(z_0, 0)$ interacts with a scalar $z_0$ because $z_0 + \alpha 0 = z_0$. On the other hand, $(z_0, 0)$ can _not_ interact with $z_0$ in the original "uses $\subseteq$ yields" inclusion.
This means we have a soundness issue: the LogUp relation can be satisfied even if the original inclusion relation isn't.
In particular, Lemma 5 (Soundness, Round 1a) in Appendix A.4 of the paper is false. To give a simple counter-example, assume that we have a single table of two columns $(x_i, y_i)$ of length $N$, a single "use" constraint $U(x,y) = (x, y)$, a single "yield" constraint $V(x) = x$, and constant yield multiplicities $m_i = 1$. Then Lemma 5 claims that the equality of rational functions
$$
\sum_{i < N} \frac{1}{X + x_i + Y y_i} = \sum_{i < N} \frac{1}{X + x_i}
$$
implies the set inclusion $\{ (x_{i}, y_{i}) \,:\, i < N \} \subseteq \{ x_{i} \,:\, i < N \}$. This is clearly not true because the rational function equation can be satisfied with $y_i = 0$ for all $i$, while the set inclusion is never satisfied (for $N > 0$).
**Impact**. Implementing lookup channels of heterogeneous dimension as specified by the whitepaper would not be secure. For `stwo-cairo`, there is no impact, because all existing lookup relations use the same dimension everywhere.
**Recommendation**. There are ways to fix the IOP to incorporate multiple dimensions. For example, the dimension could be aggregated into the scalar: $n + \alpha z_0 + \ldots + \alpha^{n} z_{n-1}$.
However, it's questionable to us if different dimensions in one lookup relation are even useful. An alternative would be to remove this possibility from the flat AIR definition.
### Computation of the Composition Polynomial Differs from Stwo Whitepaper
- **Severity**: Informational
- **Location**: cairo_air/src/lib.cairo
**Description**. The zero check (composition) round of the Stwo protocol as implemented in code deviates from the description given in the Stwo whitepaper (Protocol 1).
In particular, the whitepaper specifies that the prover sends commitments to the quotient polynomials $q^{(1)}, \dots, q^{(\tau)}$ corresponding to each of the $\tau$ AIR components. The verifier then performs the point evaluation and zero check for each table individually.
On the other hand, the `stwo-rs` and `stwo-cairo` provers both send a single commitment to the batched composition quotient.
**Impact**. The security analysis of the protocol implemented in code differs from that presented on paper.
Our intuition is that the paper version of the protocol admits a simple, straightline method for extracting individual composition quotients by leveraging the extractability of Merkle tree in the ROM. In contrast, the code version might require a rewinding argument to recover the individual composition quotients from the batched composition quotients. We do not assess whether the (round-by-round) security proof requires to extract individual composition quotients or whether rewinding security proofs are suitable to prove the desired real-world security properties of Stwo.
**Recommendation**. Align the paper and code to follow the same method. The choice of method should be dictated by the proven security properties that are required of the real-world deployment of `stwo-cairo`.
### Traces of maximal length forbidden due to off-by-one error
- **Severity**: Informational
- **Location**: pcs/quotients.cairo
**Description**.
```rust
let mut log_size = columns_per_tree_by_log_size.len();
assert!(log_size <= M31_CIRCLE_LOG_ORDER, "log_size is too large");
```
**Impact**.
**Recommendation**.
### Hash Collisions When Hashing Memory Section
- **Severity**: Informational
- **Location**: cairo_air/src/lib.cairo
**Description**. In the Poseidon version of `hash_memory_section()`, individual memory values represented as 8 u32s are concatenated into a single felt252 by `construct_f252()`, to compute the hash input.
The concatenation effectively takes the input modulo the 252-bit field, and therefore causes hash collisions between memory values that are a multiple of $p_{252}$ (the felt252 prime) apart.
This could have an impact in two possible scenarios:
- The input memory values are unchecked and can occupy the full 256-bit range. In this case, there are up to $\lceil 2^{256} / p_{252} \rceil = 32$ collisions per unique memory value.
- The input memory values are independently checked to fit in 28 9-bit limbs, as is done in the "memory id to big value" tables. In this case, since $9 \cdot 28 = 252$ and $p_{252}$ is just slightly larger than $2^{251}$, there are 2 collisions for most unique memory values.
**Impact**. In the code base at the time of audit, there is no issue, because the only memory values fed to `hash_memory_section()` are the contents of the public program, which are forced to consist of small values by the constraints of the `verify_instruction` table. However, the function seems to be intended to hash any memory section, and care will be required when applying it to arbitrary memory values in the future.
**Recommendation**. Only pack 7 u32s into one felt252 instead of 8, as is already done in `mix_u32s()`.
### Combining Multiple LogUp Relations Is Not Covered by Stwo Whitepaper
- **Severity**: Informational
- **Location**: cairo_air/src/lib.cairo
**Description**. The Stwo whitepaper's presentation of the LogUp part of Protocol 1 is less general than what is actually implemented.
The whitepaper (in Definition 6) specifies a flat AIR to consist of a _single_ lookup relation where the union over all "uses" are contained in the union over all "yields":
$$
\bigcup_{t} \mathcal{U}_t \subseteq \bigcup_{t} \mathcal{Y}_t
$$
However, to implement the Cairo AIR, `stwo-cairo` needs multiple lookup relations, each with their own independent use-yield inclusion. (In the code, independent relations are tagged with identifiers like "Opcodes", "MemoryIdToBig", "VerifyInstruction".) Using terminology from the paper, the Cairo AIR actually features multiple lookup _channels_ $\mathcal{L}$.
This generalization is not as straight-forward as it sounds, because instead of constraining the LogUp sums of each channel separately, the implementation sums them all together. Therefore, the claimed sum for every table combines the LogUp terms of all channels appearing in that table. In the end, the verifier checks that the sum total of these claimed sums equals zero.
As we [argue in the introduction](#lookups-between-the-tables), this is sound if a unique pair of interaction challenges is used for each lookup channel. This is exactly what the code does.
**Impact**. The soundness analysis of the paper doesn't cover the case of combining multiple lookup channels in the same LogUp sum, so it falls short of establishing soundness of the implemented protocol.
**Recommendation**. Align the paper with the code and cover the case of multiple lookup channels.
### LogUp Constraints Differ from Stwo Whitepaper
- **Severity**: Informational
- **Location**: cairo_air/*
**Description**. The whitepaper specifies the following constraints to verify the LogUp relation:
$$
\begin{array}{rcl}
L_{Q_{n_{t} + 1}} \cdot w^{(t)} &=& 0, \\
T_{Q_{n_{t}}} w^{(t)} - w^{(t)} &=& \sum_{j=1}^{r_t} u^{(t)}_j - \sum_{k=1}^{s_t} v^{(t)}_k, \\
L_{Q^{-1}_{n_{t} + 1}} \cdot (w^{(t)} - \gamma_{t}) &=& 0
\end{array}
$$
In particular, there are boundary constraints to fix running sums $w^{(t)}$ to the initial value of $0$ and final value of $\gamma_{t}$.
Instead, `stwo-cairo` uses the following, single constraint:
$$
T_{Q_{n_{t}}} w^{(t)} - w^{(t)} + \frac{\gamma_{t}}{N_t} = \sum_{j=1}^{r_t} u^{(t)}_j - \sum_{k=1}^{s_t} v^{(t)}_k,
$$
where $N_t = 2^{n_t}$ is the column size. This works as well because, when summing that equation over all rows, the $w^{(t)}$ terms wrap around and cancel out, resulting in the correct equation for $\gamma_t$:
$$
\gamma_{t} = \sum_{x \in D_t} \left( \sum_{j=1}^{r_t} u^{(t)}_j(x) - \sum_{k=1}^{s_t} v^{(t)}_k(x) \right).
$$
Interestingly, in this formulation the verifier doesn't care about the values of $w^{(t)}$ modulo any constant added to the entire column.
**Recommendation**. Update the paper to follow the same method as the code.
### Non-Standard Merkle Commitments Require Soundness Proof
- **Severity**: Informational
- **Location**: verifier_core/src/vcs/*
**Description**. The vector commitment scheme being used is a non-standard variant of Merkle trees. To the best of our knowledge, there are no security proofs for the extractability of such commitments or whether an IOP can be compiled to a SNARK/STARK using such commitments.
**Impact**. The code's security properties may differ from the proven security in the whitepaper.
**Recommendation**. Prove that these multi-vector and multi-sized Merkle commitments are extractable.
### Calculation of Security Bits for the PCS Only Refers to the Query Phase and Hard-Codes Conjectures
- **Severity**: Informational
- **Location**: verifier_core/src/pcs.cairo
**Description**. The formula used to compute the security level of the polynomial commitment scheme (PCS) makes multiple assumptions:
1. the calculation assumes that the PCS soundness error is dominated by the ${(1-\theta)}^s$ term from the FRI soundness error.
2. the calculation assumes that a strengthened version of the cross-domain correlated agreement theorem holds for distance parameters up to the capacity bound for Reed-Solomon codes (and therefore Circle codes).
See `fn security_bits` in [verifier_core/src/pcs.cairo](https://github.com/starkware-libs/stwo-cairo/blob/aef7d0951471c6f0474d7c1f936241095875d3d5/stwo_cairo_verifier/crates/verifier_core/src/pcs.cairo#L19).
**Impact**. These assumptions will lead to a miscalculation of the security level for users who want to operate within proven security regimes or who wish to target higher security guarantees.
For example, a user may increase the number of repetitions of the FRI query phase `n_queries` in hope of increasing the security level by `log_blowup_factor * n_queries` bits. However, it may be the case that eventually `n_queries` becomes large enough that the FRI soundness error is dominated by other terms (e.g., the folding phase). In an extreme scenario, the increase in `n_queries` might not change the security level at all.
**Recommendation**. Clearly document the assumptions underlying the security bits calculation and provide users with guidance on how to set parameters to achieve their desired security level.
### Use of `.first()` to Extract the Maximum Value of an Array
- **Severity**: Informational
- **Location**: verifier_core/src/fri.cairo
**Description**. The structs `FriVerifier`, `FriFirstLayerVerifier` and their associated methods assume that `first_layer.column_log_bounds` is sorted in descending order. In particular, there are multiple instances where `.first()` is used to extract the maximum value in this array (see `FriVerifier::commit` on line [91](https://github.com/starkware-libs/stwo-cairo/blob/aef7d0951471c6f0474d7c1f936241095875d3d5/stwo_cairo_verifier/crates/verifier_core/src/fri.cairo#L91), `FriVerifier::sample_query_positions` on line [186](https://github.com/starkware-libs/stwo-cairo/blob/aef7d0951471c6f0474d7c1f936241095875d3d5/stwo_cairo_verifier/crates/verifier_core/src/fri.cairo#L186) and `FriFirstLayerVerifier::verify` on line [340](https://github.com/starkware-libs/stwo-cairo/blob/aef7d0951471c6f0474d7c1f936241095875d3d5/stwo_cairo_verifier/crates/verifier_core/src/fri.cairo#L340)).
This is known to the developers as indicated by the documentation of the `FriVerifier::commit` methods which constructs a `FriVerifier`.
**Impact**. The current use of these structs and methods are safe. However, a developer that is not aware of this assumption may produce unsound code if not using `FriVerifier::commit` and correctly preparing its inputs.
**Recommendation**. TODO
---
This report was published on the [zkSecurity Audit Reports](https://reports.zksecurity.xyz) site by [ZK Security](https://www.zksecurity.xyz), a leading security firm specialized in zero-knowledge proofs, MPC, FHE, and advanced cryptography. For the full list of audit reports, see [llms.txt](https://reports.zksecurity.xyz/llms.txt).